引言 deeplabv3+是用于语义分割的deeplab的最新版本,其中加入了类似于U-net思想的解码器结构以及对于编码器中的Xception进行调整。该文章由谷歌团队发表,作者为Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroffff, and Hartwig Adam
原论文
网络架构
方法 这一部分对网络结构中用到的一些特殊方法和技巧做一些解释,包括空洞(膨胀)卷积,深度可分离卷积,编码器和解码器。
空洞(膨胀)卷积
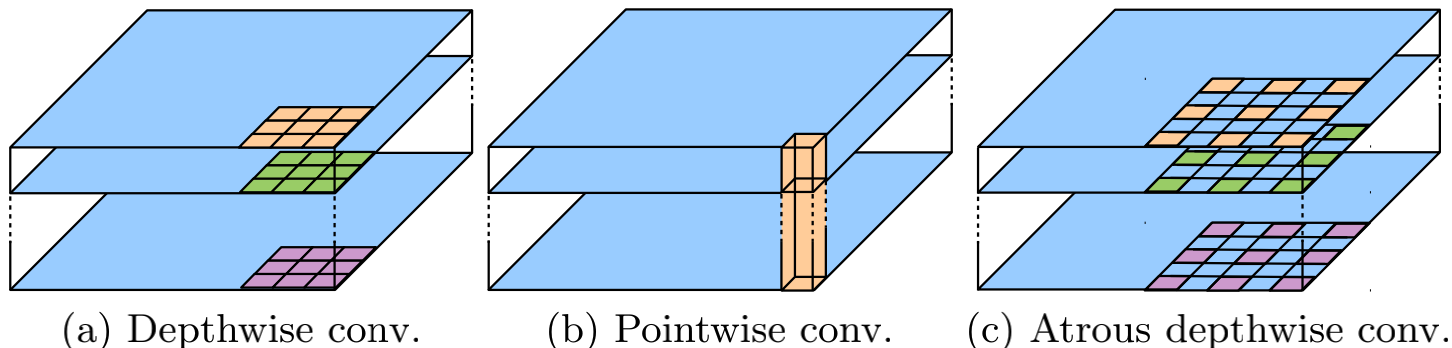
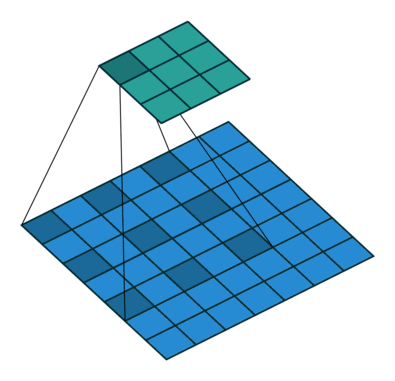
可以看出来跟普通卷积的区别就在于在普通卷积中间注入了空洞,如上图其实就是一个5*5的卷积核和特诊图卷积,但是该卷积核有一些空洞,这就是rate=2的空洞卷积。也可以看出普通卷积就是rate=1的空洞卷积。这样的首要好处就是增大了感受野。
在二维情况下它的公式就是$$y[i]=\sum_kx[i+r.k]w[k]$$
r就是空洞卷积的rate。
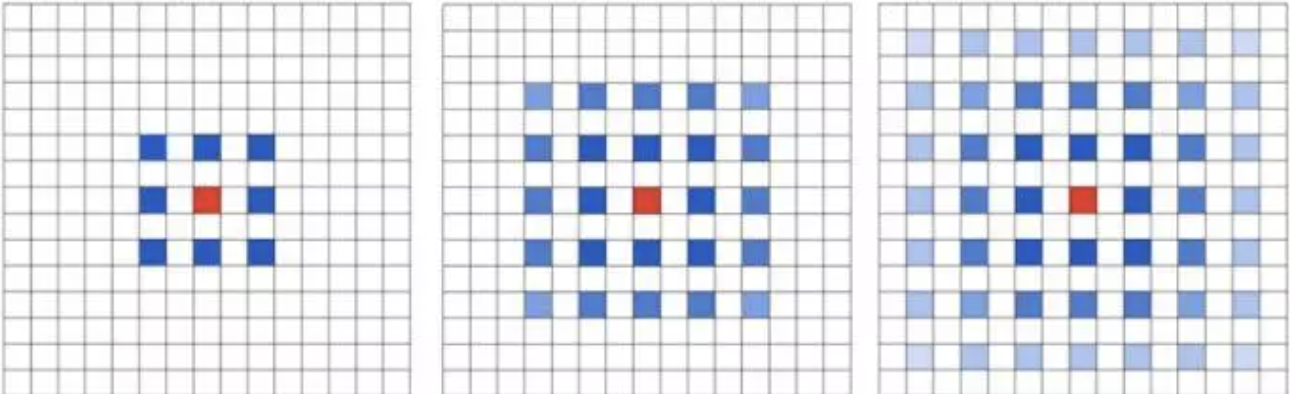
当然空洞卷积也会带来问题,如果多次的使用rate为2的空洞卷积叠加,就会发现一直是不连续的像素参与了运算,虽然感受野增大了,但是损失了信息的连续性,这对于像素级的分类也是会损失很多精度的。如下图是3次rate=2的空洞卷积叠加
当然在deeplabv3+中并不涉及到这样的问题,因为它在ASPP中是分别使用了rate=1,6,12,18和一个pooling后的结果拼接后再进行卷积,可以参考网络架构中的图,这样的方法就结合了不同的感受野的特征图,理论上模型学习能力更好。
深度可分离卷积 深度可分离卷积最主要目的就是减少网络中的计算量,它是先用1*1卷积将特征图通道数增加,再对每个通道使用一个卷积核进行卷积,下图就是第二步骤的示意图
深度可分离卷积的思想也可以用于空洞卷积上,如下图的(c)所示,可以较小计算量,使得模型更轻量。
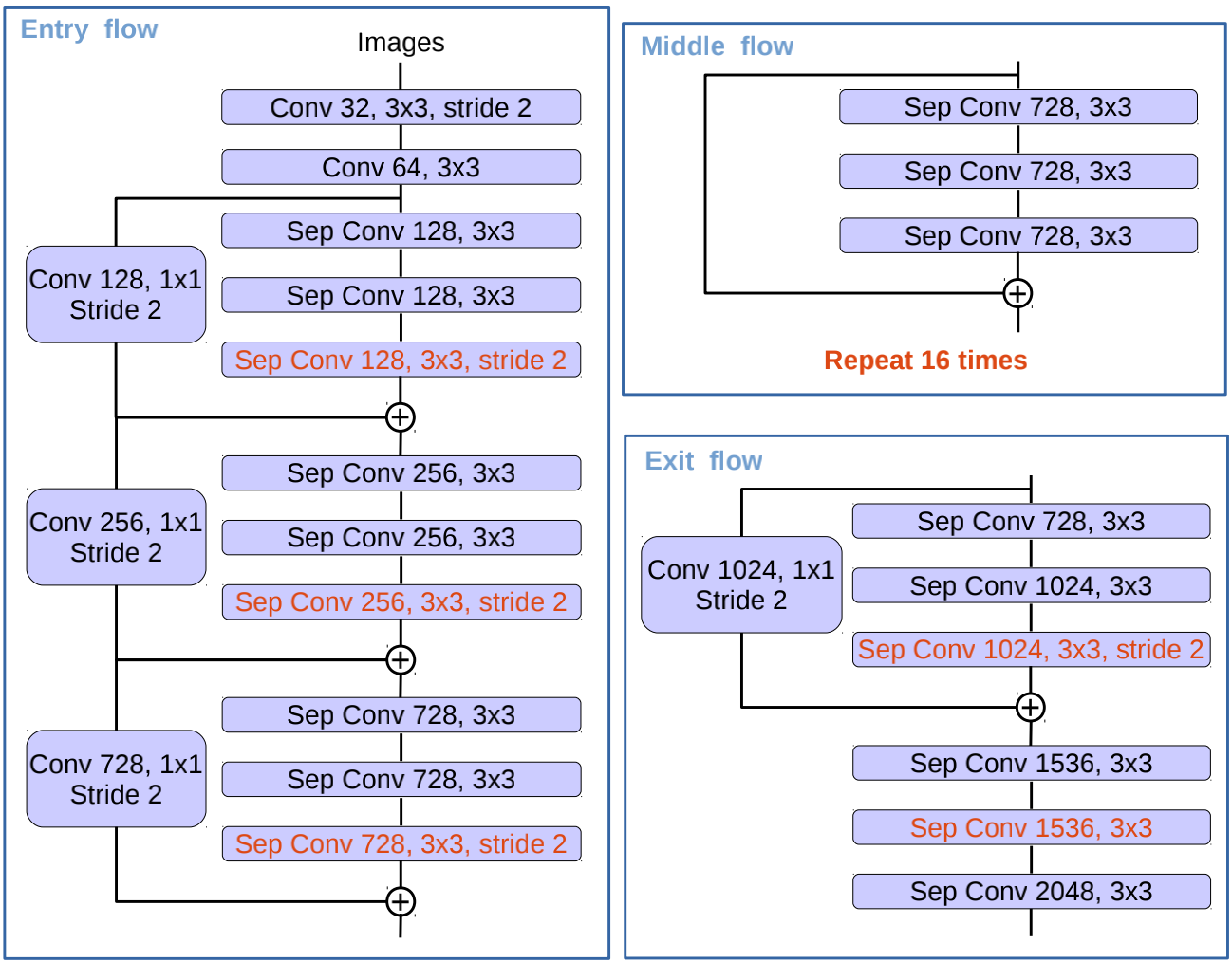
Deeplabv3作为编码器 Deeplabv3+用了它的上一个版本Deeplabv3作为编码器,主要就是作为一个特征提取的主干网络,前面的下采样部分可以使用ResNet或者Xception等特征提取网络,可以下采样16倍,也可以只采样8倍,8倍效果会更好但是有更多的计算量。采样之后就紧接一个ASPP模块,用不同rate的空洞卷积获取到不同感受野和尺度的特征图,然后将他们拼接以后再做卷积。
解码器 在之前的工作中,在编码器之后就直接使用16倍的双线性插值恢复原图像大小。但是这会使得物体边缘部分的分类出现问题,所以借用了类似U-net的思想,将ASPP输出的特征图上采样4倍后与主干网络中的低层特征进行拼接融合用于恢复边缘信息,具体操作可以对照网络架构部分的第二幅图。
对Xception的调整 同时在用Xception做主干网络时,对它进行了调整使它更适合用于语义分割任务。具体的调整在:
加深了Xception的深度(重复了16遍middle flow,原版只有8遍)。
所有的最大池化操作用带步长的深度可分离卷积替代。
在每个$3\times3$深度卷积后都加了BN层和ReLU激活函数。
修改后的图如下
我的实验 作者在论文中也贴出了自己实现的代码地址 )。作为个人学习我自己也简单做了一个实现。使用tensorflow2,主干网络用的就是原版的Xception并没有进行调整,同时ASPP模块部分使用普通卷积而没有用深度可分离卷积,数据集用的还是我在u-net文章中使用的(数据集 )。
Xception 1 2 3 4 5 6 7 8 back_bone = keras.applications.Xception(include_top=False ,input_shape=(324 ,324 ,3 )) layers_name = [ "block13_sepconv2_bn" , "block3_sepconv2_bn" ] layers = [back_bone.get_layer(name).output for name in layers_name] down_stack = keras.Model(inputs=back_bone.input, outputs=layers) down_stack.trainable = False
用了tf2中提供的在Imagenet上训练过的Xception模型作为主干网络,也尝试过VGG-16和ResNet101,发现Xception效果最好。
ASPP 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def ASPP (X,f) : x_pool = AveragePooling2D()(X) x_pool = Conv2D(f,padding='same' ,kernel_size=1 )(x_pool) x_pool = BatchNormalization(trainable=False )(x_pool) x_pool = Activation('relu' )(x_pool) x_pool = UpSampling2D(interpolation='bilinear' )(x_pool) x_1 = Conv2D(f,padding='same' ,kernel_size=1 ,dilation_rate=1 )(X) x_1 = BatchNormalization()(x_1) x_1 = Activation('relu' )(x_1) x_6 = Conv2D(f,padding='same' ,kernel_size=3 ,dilation_rate=6 )(X) x_6 = BatchNormalization(trainable=False )(x_6) x_6 = Activation('relu' )(x_6) x_12 = Conv2D(f,padding='same' ,kernel_size=3 ,dilation_rate=12 )(X) x_12 = BatchNormalization(trainable=False )(x_12) x_12 = Activation('relu' )(x_12) x_18 = Conv2D(f,padding='same' ,kernel_size=3 ,dilation_rate=18 )(X) x_18 = BatchNormalization(trainable=False )(x_18) x_18 = Activation('relu' )(x_18) x = Concatenate()([x_pool,x_1,x_6,x_12,x_18]) x = Conv2D(f,padding='same' ,kernel_size=1 )(x) x = BatchNormalization(trainable=False )(x) x = Activation('relu' )(x) return x
上采样部分可以使用二次线性插值或者转置卷积。
整体网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def DeepLabv3plus (input_shape,n_class) : x_input = Input(input_shape) x_padding = ZeroPadding2D(padding=(2 ,2 ))(x_input) image_features = down_stack(x_padding)[0 ] x_a = ASPP(image_features,256 ) x_a = UpSampling2D((4 ,4 ),interpolation='bilinear' )(x_a) x_b = down_stack(x_padding)[1 ] x_b = Conv2D(filters=48 ,padding='same' ,kernel_size=1 )(x_b) x_b = BatchNormalization(trainable=False )(x_b) x_b = Activation('relu' )(x_b) x = Concatenate()([x_a,x_b]) x = Conv2D(filters=256 ,kernel_size=3 ,padding='same' )(x) x = BatchNormalization(trainable=False )(x) x = Activation('relu' )(x) x = Conv2D(filters=256 ,kernel_size=3 ,padding='same' )(x) x = BatchNormalization(trainable=False )(x) x = Activation('relu' )(x) x = Dropout(0.2 )(x) x = UpSampling2D((4 ,4 ),interpolation='bilinear' )(x) x = Conv2D(n_class,(1 ,1 ),padding='same' ,activation='softmax' )(x) model = keras.Model(inputs=x_input,outputs=x) return model
同样上采样部分可以使用二次线性插值或者转置卷积。
结果
以上是训练集的图片,最下面是网络分类的结果,可以看到几乎一致。在训练集上最高能达到96%的准确率还要高,但是在测试集上却在91%左右,可能由于图片不足以及训练集和测试集分布不一致导致的(训练集行人较少,测试集则都是行人,实际也是在行人等小物件分类出现不足)。但是总体来看还是可以看出deeplabv3+的实力还是不俗的。
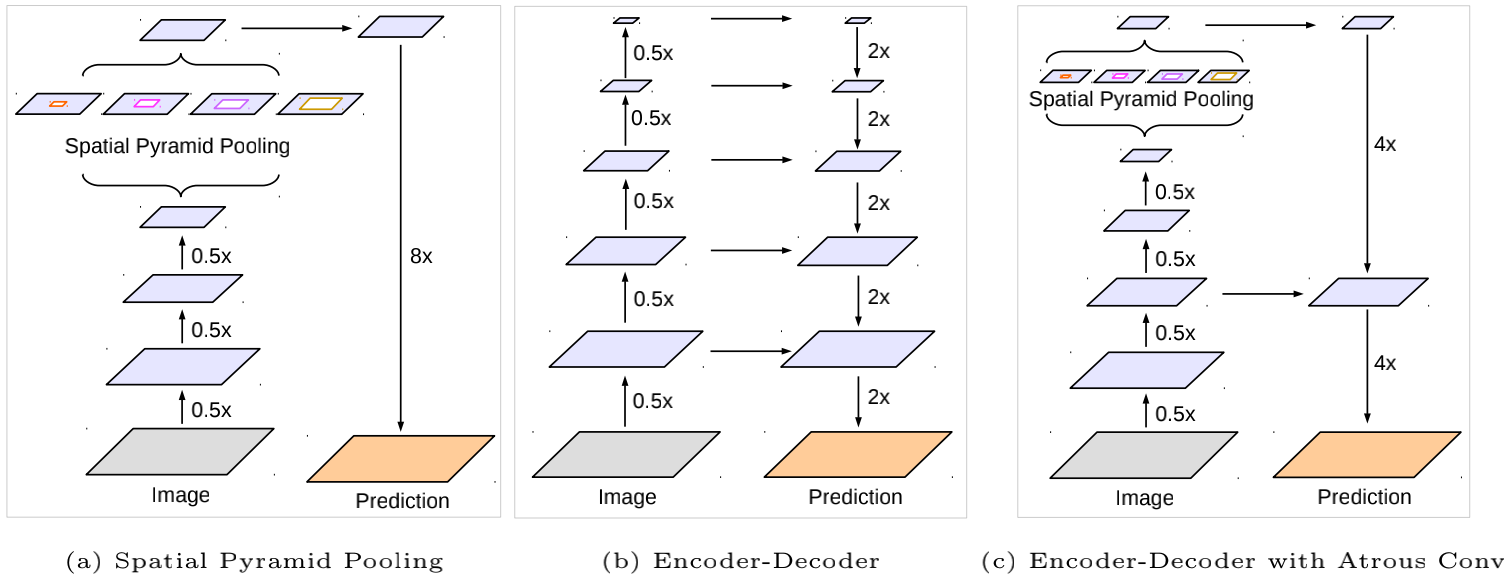 )网络的整体架构如上图的(c)所示,它加入了编码-解码的思想,因为在编码的时候经过步长卷积或者池化层,细节信息有所丢失。所以在解码的时候与低层的信息相连接,可以有助于恢复图像边缘信息。更为详细的图如下所示
)网络的整体架构如上图的(c)所示,它加入了编码-解码的思想,因为在编码的时候经过步长卷积或者池化层,细节信息有所丢失。所以在解码的时候与低层的信息相连接,可以有助于恢复图像边缘信息。更为详细的图如下所示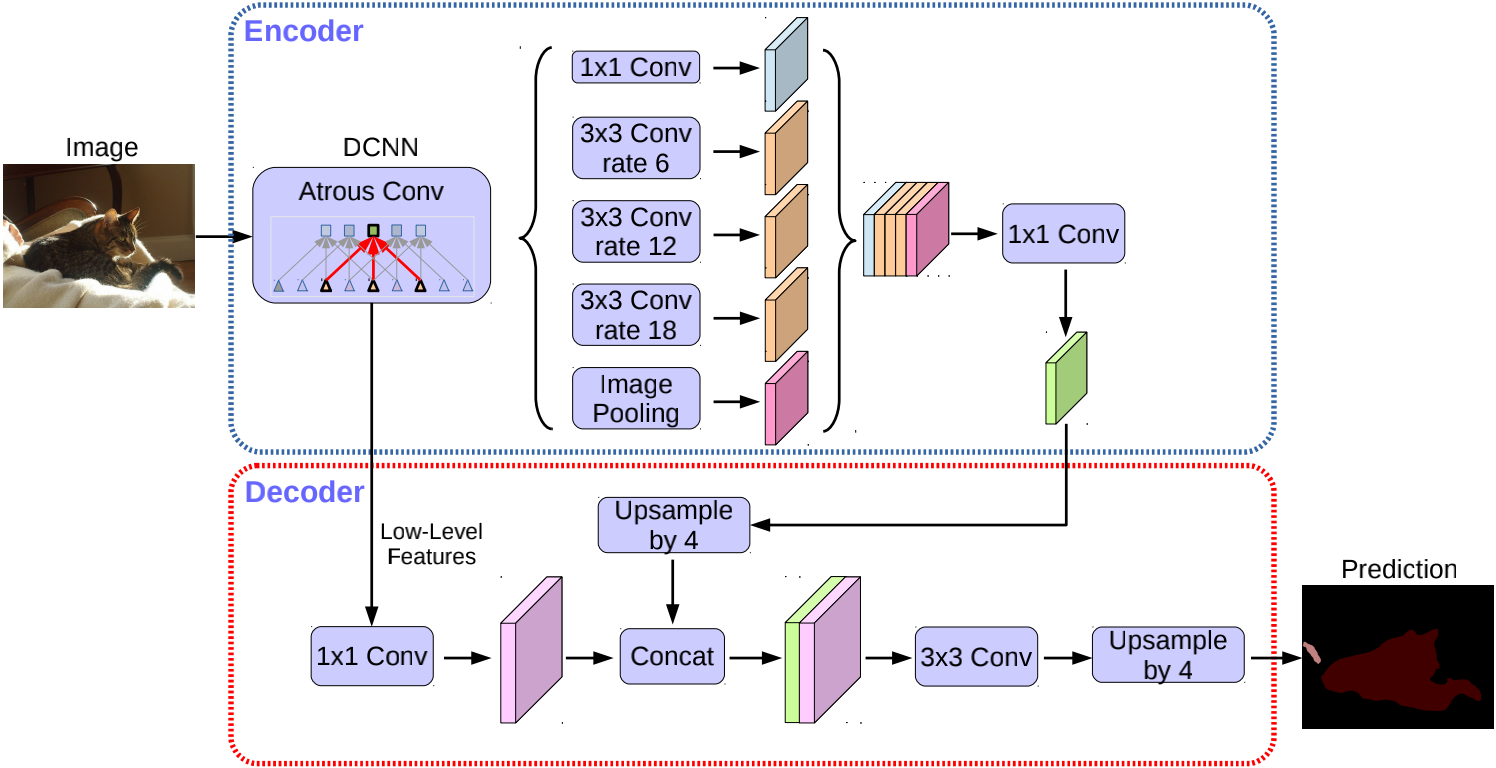
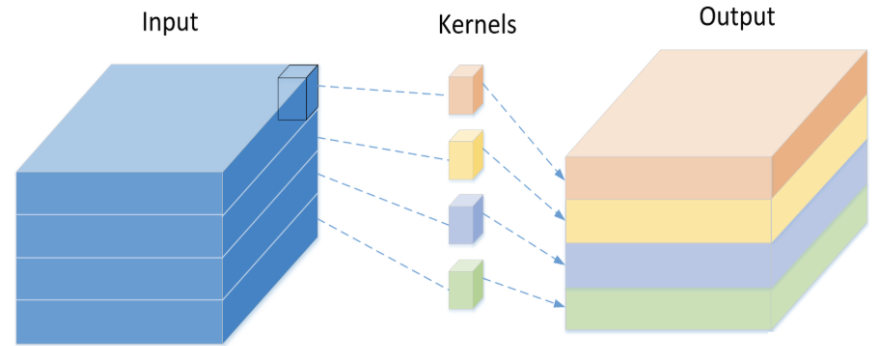 这样的方法比起普通卷积在学习能力上会有一点点欠缺(不是特别明显),但是计算量少了非常多,可以减少为传统卷积的$\frac{1}{9}$-$\frac{1}{10}$左右。
这样的方法比起普通卷积在学习能力上会有一点点欠缺(不是特别明显),但是计算量少了非常多,可以减少为传统卷积的$\frac{1}{9}$-$\frac{1}{10}$左右。